

Are you sick of sifting through mountains of data across several databases to find answers, only to realise that five different entries describe the exact same, one piece of information you actually need?
If this is one of your pain points, then it could be time to invest in data warehousing.
A data warehouse provides a quick and easy way to access data that, if set up correctly, offers your business a single source of data truth that’ll save you time, money, and hours of painstaking data querying.
In this blog, we’ll explore what a data warehouse is, how to go about building one, and the biggest mistake to avoid when setting up your new data warehouse.
What is a data warehouse?
A data warehouse is a ‘data store’ that is optimised for data storage and retrieval.
You’ve probably heard of dimensional modelling and Business Intelligence (BI) as answers to your analytical business needs when it comes to data. We’ve talked about the role of Business Intelligence before, and its ability to process and visualise data.
The data warehouse sits beneath these tools, and when correctly implemented, can maximise their efficiency – allowing the data analytics tools to quickly draw upon high-quality data.
Way back in 1996, dimensional modelling thought leader, Ralph Kimball, identified in his book The Data Warehouse Toolkit that a data warehouse aims to address the following concerns facing businesses, framed as common challenges audible in workplaces:
“We collect tons of data, but we can’t access it.”
“We need to slice and dice the data every which way.”
“Business people need to get at the data easily.”
“Just show me what is important.”“We spend entire meetings arguing about who has the right numbers rather than making decisions.”
“We want people to use information to support fact-based decision making.”
These concerns were outlined almost three decades ago but still might sound all too familiar for businesses today. Accessing and reporting data remains a challenge, and data warehousing presents part of the solution.
 A data warehouse can provide your business with a single source of data truth.
A data warehouse can provide your business with a single source of data truth.
Much like a real-life warehouse, a data warehouse provides a centralised location for all of your data throughout your entire organisation, making it easier to access the information you are searching for quickly and with more organisational-wide clarity on the type of information being found and stored.
This ability to produce high quality, quick-to-access data, is one reason data warehousing is highly sought after in so many industries – industrial, finance, banking, health, manufacturing – but it is not the only reason.
Data warehousing also provides a single source of truth (SSOT).
SSOT refers to the practice of structuring all your high-quality data in a singular place, so that all levels of your organisation are on the same page when accessing, analysing, and reporting on data.
Whether you’re utilising the infrastructure of a data warehouse to store your existing data or building a data warehouse to store fresh information – you’re taking a step towards achieving a SSOT.
How does a data warehouse work?
A data warehouse, within the dimensional modelling framework, is an analytical and reporting database. It is a system designed and optimised to support analytics (i.e., reporting and BI) following data retrieval – or getting data out.
Data warehousing first involves the ingestion of data from elsewhere. This can be from a single data source within your business, or multiple sources (e.g., CRM, billing, ERP, flat files, supply chain management etc.). The resulting historical data is de-normalised and stored through either the extract, load, transform (ELT) or the extract, transform, load (ETL) process – ready for user analysis, mining and reporting.
There are several differences between ETL and ELT. One of the main distinctions is that ELT removes the data staging process – a key temporary storage component between the extract and transform stages in ETL – instead leveraging the data warehouse’s ever-growing capabilities to do these basic transformations.
Already commonly used in conjunction with data lakes, ELT is becoming the new industry standard for data warehousing thanks to modern technologies and cloud-based platforms that support faster processing, memory and storage capabilities.
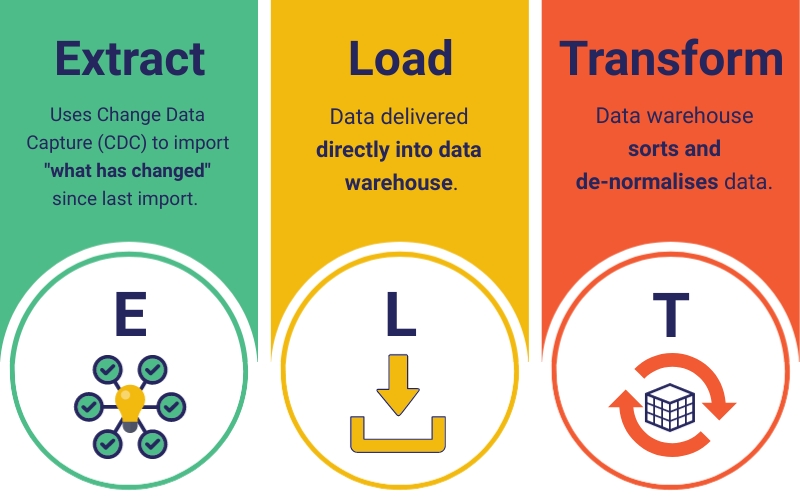 Data warehousing is moving toward an ELT approach as the preferred method for ingesting data thanks to more advanced and cloud-based technologies.
Data warehousing is moving toward an ELT approach as the preferred method for ingesting data thanks to more advanced and cloud-based technologies.
Data warehouses are highly de-normalised systems designed to get data out in an optimised way for the end-user and so are defined as a form of online analytic processing (OLAP).
Online transaction processing (OLTP) – designed for getting data in – and OLAP are not competing technologies.
The OLTP and OLAP co-exist – the former feeding information into the warehouse, and the latter providing an avenue for more effective analytical processes on the other side. An example of an OLTP and OLAP coexisting could be TilliT, updating real-time information on a manufacturing plant floor and feeding this information back into an established data warehouse.
There’s more than one way to build a data warehouse, all having the same end goal. In this blog, we’ll explore my preferred methodology – Kimball’s dimensional modelling approach utilising a Star Schema design.
 The Star Schema is the underlying dimensional model of the data warehouse.
The Star Schema is the underlying dimensional model of the data warehouse.
Let’s take a step-by-step look at how the data warehouse works in a Star Schema design:
- Data comes in from one or many data sources and is integrated into the data warehouse environment – with more operations becoming cloud-based.
- The data warehousing de-normalisation process of ELT (or ETL) takes place. This is the simplifying, or cleaning of complex data with differing dimensions from one or multiple data sources into one conformed set of dimensions within the data, creating a single source of truth. This ensures the data is subject-oriented and more easily queried by users.
- Data is time-variant and non-volatile. Historical data remains unchanged, and new data can be imported and updated – typically on recurring schedules – using an OLTP of your choosing. Change Data Capture (CDC) during the extract phase of ELT updates data based on “what has changed” since the previous import, occurring in near real-time if the size and complexity of the load allow it.
- Data is easily retrieved from the data warehouse for reporting, analytics and data mining.
Having access to meaningful data supports strong decision-making based on an understanding of the past, present, and even future or potential unknowns thanks to smart BI tools that can identify patterns or trends.
A good data warehouse serves you data accessibility in an optimised and performant way.
Want a GOOD data warehouse? Conformed dimensions are key!
The number one rule I’ve found best to follow when creating a data warehouse is that you must have conformed dimensions.
A dimension is something that describes a piece of data. In the context of retail sales, for example, dimensions could refer to the date, product, store, promotion, customer, or employee.
A data warehouse, unlike an OLTP, does not delete redundant data – rather, it utilises ALL available data to create our single source of data truth. This allows end-users a better ability to integrate their data with ad hoc queries and ‘slicing and dicing’, thanks to the data warehouse’s Star Schema design.
When data comes into the warehouse, we know there is an ELT phase. During this portion of ingesting data into the warehouse, to ensure that all the data within this design can be easily and quickly queried by all users who need it – we need conformed dimensions.
Utilising Kimball’s Enterprise Bus Matrix, you should identify each business process and the dimensions within this process. You’ll need to engage with all stakeholders involved in the data management and access to identify these and agree upon the common dimensions.
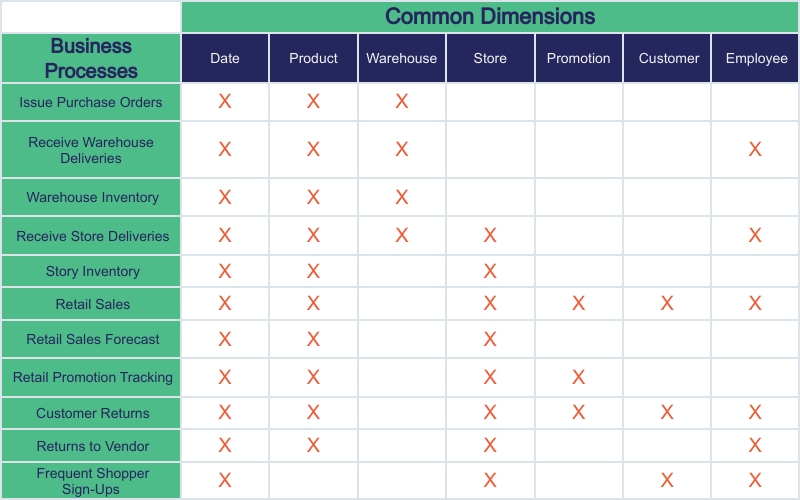 Kimball’s Enterprise Bus Matrix (from The Data Warehouse Toolkit) is critical to identify common dimensions and facts.
Kimball’s Enterprise Bus Matrix (from The Data Warehouse Toolkit) is critical to identify common dimensions and facts.
Imagine, the CIO of your business accesses the retail sales data for an upcoming monthly report. What if the dimensions such as date, product, store etc., are not clearly outlined and agreed upon?
Data would enter the warehouse with differing dimensions describing the same piece of information (e.g., a customer – could be entered as John Doe, J. Doe, Mr Doe, J.D. etc.).
Similarly, you should define the grain of the fact within the data warehouse early. Facts are central to the Star Schema design – your conformed dimensions (e.g., customers, times, channels, products etc.) feeding the facts (e.g., in sales – the amount sold, quantity sold etc.) to deliver the easily accessible data inside the data warehouse.
If you identify the correct fact grain early, you enhance your data visibility; the finer the grain, the more detail you’ll be able to draw upon when a user produces a report.
By conforming dimensions within your data warehouse, you’re ensuring a consistent language across the enterprise, enabling the end-user faster access to vast amounts of information and more confidence in the accuracy of the query results.
Make smarter, data-driven decisions with data warehousing.
Earlier in this blog, I referred to some of the common workplace concerns around data. Things like, collecting lots of data but being unable to use it, wasting time trying to make sense of reports when you could be making data-driven decisions.
Many of these data dilemmas are present in businesses around the world, and there are ways a data warehouse can remove these frustrations.
Data warehousing can help you quickly access data from all areas of your business in one location, with greater clarity and simplicity for end-users thanks to a single source of truth.
With data warehousing, you can gain access to high quality, meaningful data with high-speed query performance to help make better, data-driven decisions for your business.





